







Forum de mathématiques - Bibm@th.net
Vous n'êtes pas identifié(e).
- Contributions : Récentes | Sans réponse
#26 Re : Café mathématique » Fond du problème des probabilités (titre probisoire) » 20-10-2016 17:31:59
Bonsoir,
@ Milos
Milos a écrit :"Moi a écrit" - c'est très caractéristique de votre infatuation projective : "vous êtes totalement sûr de vous"
Vous êtes vraiment psychiatre ? C'est la seconde fois que vous faites une erreur psychologique. Ce serait mieux qu'il n'y en ait pas une troisième.
Je peux vous garantir que je suis psychiatre, psychiatre des hôpitaux, etc...
Pour votre infatuation, ça n'est pas un terme médical mais un mot d'usage normal, chaque lecteur du forum se fera sa propre idée sans plus ni moins de pertinence que n'en a mon appréciation.
Pour les mécanismes projectifs, c'est évidemment plus technique. On peut le considérer comme un mécanisme normal (prêter ses sentiments à autrui, au moins pour partie, est inévitable même pour simplement dialoguer : ce que dit autrui pouvant avoir plusieurs sens apparentsi, cette démarche permet de prêter un sens ou quelques uns plausibles et "intelligibles", à ce qu'on entend).
Bien sûr, un petit tour sur Google vous permettra de voir que les mécanismes genre identification projective sont des moyens de défense observés particulièrement pour les adultes, chez les paranoïaques.
J'ai dit que je ne fais pas de diagnostic à distance, et ne prétends en rien que vous soyez malade.
Mais quand vous dites que je suis "totalement sûr de moi" alors que précisément si je pose des questions ici c'est justement à cause du contraire, je ne peux faire autrement que vous me prêtez des sentiments de certitude que vous-même semblez très souvent avoir.
#27 Re : Café mathématique » Fond du problème des probabilités (titre probisoire) » 20-10-2016 00:50:58
On ne sait même plus à qui vous écrivez..
Mais on sait qui vous citez :
Copie de mon message 13H29
Moi a écrit :Bonjour,
Apparemment, vous ignorez tout ou presque de ce qu'est la loi normale et ce qu'on appelle une erreur.
On peut supposer que vous avez lu le papier "Notions d probabilités" et "Incertitude et erreurs", avant de lire ceux qui parlent de papillons et de taille des enfants. De toute façon vous n'avez rien compris.
D'abord TOUTE MESURE EST ENTACHEE D'UNE ERREUR. Vous confondez erreur et faute. C'est très caractéristique de votre ignorance du sujet dont il s'agit.
Concernant votre très jolie courbe, vous avez choisi de faire 30 classes, choisissez d'en faire 28 ou 32 vous verrez qu'il n'y aura plus de classe "monstrueusement éloignée".
Votre méconnaissance de ces notions est réellement dangereuse, d'autant que vous êtes totalement sûr de vous.
Bonne chance à votre entourage.Je viens de faire le calcul de l'évolution semaine par semaine, il n'y a strictement rien de caractéristique.
Régression linéaire Y=A + B * X nbpts=79 A = 66.4 B = 0.0633 R2 = 0.028 (emq=8.489)
Juste peut-être une petite évolution saisonnière. Mais cela demanderait une étude plus détaillée, sans grand intérêt pour un seul hôpital.
Donc, à part la vérification des lois que l'on connait, votre fichier n'apporte pas vraiment d'information intéressantes.
"Moi a écrit" - c'est très caractéristique de votre infatuation projective : "vous êtes totalement sûr de vous"
De plus je ne parlais ni de faute ni d'erreur sur ces données, je disais justement qu'il ne pouvait qu'y en avoir aucune dans cet exemple précis, à moins que l'ensemble des équipes des urgences ne soit bourré au point de ne plus savoir quel jour on est, ou de voir doublement les patients qui arrivent.
C'est une option d'un des modes de calcul d'un de mes programmes qui a choisi par défaut 30 classes avec ce nombre de couples de données. Un autre mode de calcul prend 10 classes.
Vous ne savez décidément que faire des régressions sur ce modèle A + BX, après quoi vous dites "juste peut-être une variation saisonnière", au pif.
"Peut-être", ça vaut quel risque d'erreur ?
#28 Re : Café mathématique » Fond du problème des probabilités (titre probisoire) » 19-10-2016 22:12:44
Bonsoir,
La prochaine fois que vous me suggérez de prendre 28 ou 32 classes (vous devriez proposer d'en faire de 1 à 100), vous m'envoyez le message avec une demande d'accusé de réception + accusé de lecture, comme je n'ai rien vu de ça.
Mais j'ai essayé avec 10 classes comme vous et ça n'est pas mieux.
Ben, oui, j'ai bien reçu tout ça.
Je vous ai suggéré de changer le nombre de vos classes, par exemple en faire 28 ou 32 au lieu de 30, vous l'avez fait ?
Cela dit, je suis parfaitement sérieux, si vous démontrez que votre liste ne suit pas la loi normale et que les mesures par semaines sont indépendantes et aléatoires, c'est à dire qu'il n'y a pas eu d'évènement majeur durant cette période, par exemple un accident touchant de nombreuses personnes, alors, cela justifie une information à l'académie des sciences. Ce n'est pas un gag, c'est tout à fait sérieux.[Edit] Si on veut exploiter ces données, on peut aussi voir l'évolution semaine après semaine. Ce n'est pas sans intérêt, je ferai cela demain.
Bonne soirée.
#29 Re : Café mathématique » Fond du problème des probabilités (titre probisoire) » 19-10-2016 21:08:00
Bonsoir,
@ Milos,
Manifestement vous avez trouvé un contre-exemple aux lois connues depuis plus de deux siècles. Vous devriez faire une communication à l'académie des sciences.
C'est un gag ? je vous ai envoyé ce graphe deux fois, la dernière fois hier encore en PJ au cas où votre programme de messagerie ne saurait pas afficher des graphes.
Et vous savez que ce n'est pas un contre-exemple mais le graphe en 30 classes des mêmes données que je vous ai transmises et que vous "analysez" ci-dessus.
#30 Re : Café mathématique » Fond du problème des probabilités (titre probisoire) » 19-10-2016 20:14:06
Bonsoir;
Milos a écrit :Ces données sont exhaustives de toutes les urgences qui ont été enregistrées jour par jour du 1/1/2015 au 30/6/2015, dans un hôpital de seconde catégorie (venant de suite par importance administrative, après un CHU).
Les moyennes est assez comparable, sauf que les jours 2 et 3 qui paraissent plus élevés.
Les écart-type sont comparables.
On peut ainsi vérifier que la loi des grands nombres et le TCL sont bien vérifies.
Le graphe ci-dessous montre comme le total suit une loi supposée "des grand nombres" (normale ?):
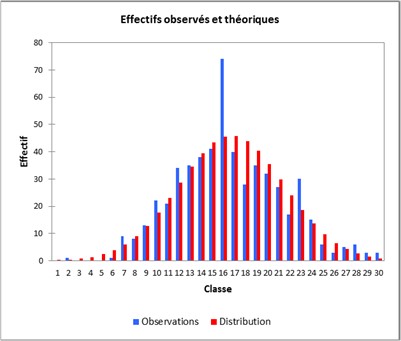
On voit en regardant par exemple la classe 16 sur les 30, que ce serait presqu'aussi bien une loi triangulaire que normale (bon j'exagère, mais quand même, un effectif de 74 quand 45.535 est espéré selon la loi normale - que les tests excluent d'ailleurs avec un risque p très bas)
#31 Re : Café mathématique » Fond du problème des probabilités (titre probisoire) » 19-10-2016 17:39:24
Bonsoir,
Le fichier que Milos m'a communiqué répond à cette préoccupation, mais comme il m'a été fourni en privé, je ne suis pas en droit de l'utiliser. (fin d'introduction).
Si, je vous permets de l'utiliser. Vous pouvez même le donner in extenso sur le forum, ça n'occasionnerait aucun inconvénient à part le plutôt grand volume que ça donnerait à votre message.
#32 Re : Café mathématique » Robustesse d'une régression linéaire » 18-10-2016 21:11:32
Cher Freddy,
Je recommence donc ce soir, avec un modèle comme conseillé :
>LET ERR_N_500 = ZRN(0,1)
>LET YPLUSBLANC =379 + 24 * XBLANC +ERR_N_500
XBLANC restant tiré au sort avec une loi normale(40,10) et ERR_N_500 rectifiée à ZRN(0,1)
Cette fois les résultats sont trop beaux, j’ai du vérifier l’absence de bourde :
379.286 (ecart type 0.401) et 23.995 (écart-type 0.10)
Avec un R2 de 1.000 ( !)
Et
Lilliefors 0055 p-value 0.590
SW 0.991 p 0.751
Anderson Darlong 0.379 et p>0.15 (non calculable précisément)
Durbin-Watson D 2.233 et F1 AC -0.141
Ci-dessous les résidus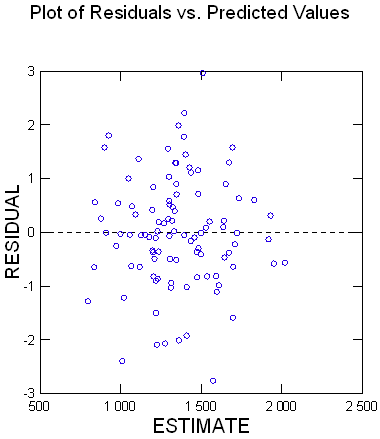
Donc grâce à tes excellents conseils ça marche même trop bien.. :-)
Reste la question de mes 27 couples de départ, même si R^2 n’est pas trop mauvais, pourquoi trouves-tu les résidus mauvais, etc.. quels sont les éléments que je n'ai pas captés ?
Merci en tout cas à toi, amitiés,
#33 Re : Enigmes, casse-têtes, curiosités et autres bizarreries » Impact de la foudre. » 17-10-2016 23:47:39
@Dlzlogic
@Milos, je ne me suis jamais défilé, donc j'attends avec impatience ces données. Si elle me sont envoyées par mail, je ferai une réponse par mail (peut-être un petit commentaire en public), sinon je détaillerai en public. (tous les formats me conviennent, mais il faut tout de même quelques détails sur le contexte et le but recherché).
je viens d'envoyer en PJ par mail ces données, exhaustives, au format Excel 97-2003 : 557 lignes, les dates consécutives et le nombre de patients enregistrés par jour aux urgences.
Le contexte est évident me semble t-il, puisque aucune exclusion n'est faite.
Le but n'a rien à voir, c'est moi qui souhaitais ces données pour effectuer un travail préalable à une analyse de tendance sur les urgences psychiatriques qui en forment un sous-ensemble minuscule.
Ces données m'ont donc été données sans aucune arrière-pensée par le responsable du département d'information médicale, qui n'a fait aucune analyse autre que descriptive pour la tutelle et tous les services, pas seulement les urgences.
Il y a bien dans les données un facteur évident d’auto-corrélation, repéré d'instinct par le DIM (mais que les urgentistes trop proches sans doute du terrain ne semblent pas avoir vu) et que je vous laisse trouver.
@+
#34 Re : Enigmes, casse-têtes, curiosités et autres bizarreries » Impact de la foudre. » 17-10-2016 22:25:09
Bonsoir,
Je me permet de rappeler que vous avez dit que vous allez m'envoyer un fichier de plus de 500 données et "voir ce que je pouvais en tirer". Je n'ai toujours rien reçu.
Mais vous ne m'aviez pas dit que vous vouiez de ce fichier, si vous confirmez je vous l'envoie dès que vous le demandez.
Un format Excel, 97-2003 ou autre vous convient ?
Répondez moi et je vous l'envoie aussitôt (enfin, comme je travaille, dès le soir où j'ai du temps - voire le matin comme je dors peu.
Confirmez seulement, aucun problème.
#35 Re : Enigmes, casse-têtes, curiosités et autres bizarreries » Impact de la foudre. » 17-10-2016 21:34:20
Bonsoir,
Votre intervention est très regrettable. La question posée est un problème strictement mathématique. Vous n'avez aucune idée de l'origine de la question posée à la base et vous tirez des conclusions sur les moyens d'y répondre !
J'avais bêtement cru que vote question était celle que je cite ci-dessous, d'après votre propre texte:
Pour clarifier les idées, prenons l'exemple de l'étude de l'impact de la richesse sur le
rachitisme des enfants. Dans un pays, on a établi une liste d'enfants avec les informations
suivantes
Comme vous posez un problème statistique qui vise à connaître les occurrences du rachitisme à partir de 13 variables, commencer par définir comment on dit que ce rachitisme existe ou pas, et éventuellement sa sévérité, est un problème "strictement mathématique" ?
Mais puisque vous dites que je n'ai "aucune idée de l'origine de la question posée à la base" alors que vous donnez ça dans l'énoncé, qui ne ressemble pas tellement à un "problème strictement mathématique" mais à une question d'épidémiologie banale et qui donc renvoie aux méthodes classiques d'épidémiologie, dont je suis bien sûr que vous avez des notions très précises..
Vous avez raison, la correction vaut mieux ne pas en dire plus.
#36 Re : Enigmes, casse-têtes, curiosités et autres bizarreries » Impact de la foudre. » 17-10-2016 21:07:28
Bonsoir,
@ Léon,
Autre exemple : "sur ce bateau il y a 100 chèvres et 20 moutons, quel est l'age moyen des animaux ?" Si on est éleveur et qu'on connait l'age des animaux qu'on fait voyager par bateau, on pourra répondre à la question, ce n'est pas qu'une question de mathématique mais de connaissance dans un certain domaine, mais il faudra aussi connaitre la notion mathématique de "moyenne pondérée".
Je citerais par exemple dans le même système de pensée, une page de votre site :
http://www.dlzlogic.com/aides/Lorenz_Gini.pdf
Comme vous voulez avoir une idée de l'incidence ou de la prévalence du rachitisme relativement aux différents paramètres cités, si on voulait faire une étude réelle il faudrait déjà avoir une définition du rachitisme, ou de sa gravité.
Vous ne donnez aucun définition du rachitisme ni des critères que vous choisissez pour le détecter et éventuellement d'évaluer sa gravité, ce qui est plus que gênant comme c'est la valeur dépendante. Généralement la densité osseuse est un critère important, mais cette densité elle-même est difficile à mesurer, avec pas mal de paramètres pouvant l'influencer sans forcément de lien avec le rachitisme.
Et votre indice de Gini s'il mesure peut-être la répartition des richesses dans une population, ne me semble pas en rapport direct avec la richesse du foyer qui dépend forcément de la richesse du pays : les parents ou équivalents ont-ils les moyens d'acheter du lait, etc.. qui est elle une valeur directe de la capacité de fournir à un enfant de quoi éviter un rachitisme.
Pourquoi donner ainsi des indications sur l'une seule des 13 variables que vous pensez impliquées, si le problème lui-même, la façon de dire s'il est présent et d'évaluer sa gravité, n'est pas précisée ? Et si la plupart des pays pauvres n'ont pas les moyens de faire des densitométries osseuses, on peut présumer que s'ils n'en ont pas les moyens, ce n'est pas sans rapport avec la pauvreté des foyers où on risque de trouver davantage d'enfants rachitiques..
Vous avez raison, ma profession ne vous regarde pas. Peut-être un peu quand même quand vous évoquez un problème en rapport avec cette profession..
#37 Re : Café mathématique » Robustesse d'une régression linéaire » 17-10-2016 19:07:49
Cher Freddy,
En m’y reprenant plus sérieusement, cette fois je n’ai pas oublié d’ajouter le bruit à y, et donc avec les préalables suivants :
XBLANC est simulé avec une loi normale de moyenne 40 et d’écart-type 10
(moyenne mesurée, 40.532, écrat-type 10.877 ; Shapiro-Wilk 0.988, p-value bilatérale 0.532 ; Anderson-Darling 0.312 p-value bilatérale 0.545 ; Lilliefors p-value bilatérale 0.399 ; Jarque-Bera p-value bilatérale et alpha 0.05).
L’erreur ajoutée à YPLUSBLANC = XBLANC*24 + 379 est ERR_N_500 (loi normale centrée 0 et écart-type 100) et j’ai pour ERR_N_500
Moyenne 22.409, écart-type 474.901 ; S-W 0.990. p 0.631, alpha 0.05 ; A-D p 0.576, alpha 0.05 ; Lilliefors p 0.391 alpha 0.05 ; Jarque-Bera p 0.482 alpha 0.05.
J’ai abrégé ci et là en ne donnant pas toutes les valeurs que me donne XLSTAT pour ces tests (genre D et D normalisé pour Lilliefors, etc.)
Aussi bien XLSTAT que Systat me donnent les mêmes valeurs de l’équation
YPLUSBLANC = 560 + 20*XBLANC (donc au lieu de 379 + 24*x) à toutes les décimales près (j’ai arrondi) et les mêmes R^2 (0.176) et ajustés (0.167). Il me semble donc que leur méthode de calcul n’est pas en cause.
Je suppose intuitivement que cette mauvaise corrélation pourrait être en partie liée au fait qu’en prenant X selon une distribution normale, peu de points sont éloignés de la moyenne, alors que la méthode de régression donne sans doute des résultats plus précis quand beaucoup de points en sont distants ? Quand je prenais la répartition uniforme de X depuis 20 à 100 de 5 en 5, la corrélation était bien meilleure.
Il reste la question de la qualité du générateur aléatoire qui est celui de Systat, et que ce programme indique comme étant de type Mersenne Twister. Quand je lis sur cet algorithme, je vois pourtant que cette méthode serait assez valable sauf besoin pointu du genre cryptographie.
Je te joins ci-dessous le graphe des résidus.
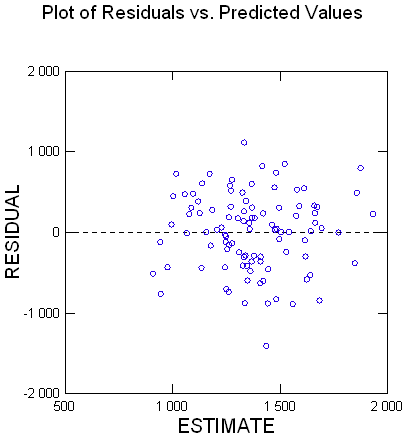
Si tu souhaites toujours que je donne les valeurs d’origine, j’aimerais avec ta permission de les donner en MP, pour éviter de dévier sur des considérations historiques ici, où ce n’est pas ni ne doit être le lieu de ces considérations.
Bien amicalement, @+
#38 Re : Café mathématique » Robustesse d'une régression linéaire » 16-10-2016 19:03:59
Bonsoir,
Je m'y suis repris et cette fois je ne suis pas déçu, au point que je croyais avoir fait une erreur et ai recommencé !
La corrélation calculée est de 1..
Et le modèle parfait, 379, 24*x
Dependent Variable
YPLUSBLANC N 100
Multiple R 1,000
Squared Multiple R 1,000
Adjusted Squared Multiple R 1,000
Standard Error of Estimate 0,000
Regression
Coefficients B = (X'X)-1X'Y Effect
Coefficient Standard Error Std.Coefficient Tolerance t p-Value
CONSTANT 379,000 0,000 0,000 . . .
XBLANC 24,000 0,000 1,000 1,000 . .
Analysis of Variance Source SS
df Mean Squares F-Ratio p-Value
Regression 6 746 515,831 1 6 746 515,831 . . Residual 0,000 98 0,000
Test for Normality
Test Statistic p-Value
K-S Test (Lilliefors) 0,444 0,000
Shapiro-Wilk Test 0,632 0,000
Anderson-Darling Test 20,026 < 0.01* *The p-value cannot be precisely computed.
Durbin-Watson D-Statistic 0,023 First Order Autocorrelation 0,980
Information Criteria AIC . AIC (Corrected) . Schwarz's BIC .
Bref comme disait Boris Vian, il y a un défaut, j'y retourne immédiatement..
@+
#39 Re : Café mathématique » Robustesse d'une régression linéaire » 16-10-2016 18:41:53
Bonsoir,
J'ai du me planter, la corrélation s'est complètement effondrée en prenant n avec une moyenne de 40 et un écart type de 10 et le reste égal par ailleurs.
J'ai d'ailleurs eu du mal à fusionner le tableau avec un x normal avec le précédent, j'ai du faire une fausse commande d'autant qu'il me fallait ensuite taper en ligne de commande la nouvelle valeur de "YBLANC".
J'y reviendrai donc, mais je ne serai plus en vacance demain et donc lent..
Amitiés
PS : j'ai regardé les offres de SAS pour amateurs, j'attends la réponse, c'est peut-être prématuré. Dans mon métier, il me semble que l'ATIH utilise SPSS pour les données qu'on leur remonte.
#40 Re : Café mathématique » Robustesse d'une régression linéaire » 16-10-2016 13:41:21
Bonjour Freddy,
J'ai fait ce que tu demandes et cette fois je trouve :
▼OLS Regression
Dependent Variable YPLUSBLANC
N 100 Multiple R 0,991
Squared Multiple R 0,983
Adjusted Squared Multiple R 0,983
Standard Error of Estimate 470,070
Regression
Coefficients B = (X'X)-1X'Y Effect Coefficient Standard Error Std.Coefficient Tolerance t p-Value
CONSTANT 249,373 98,995 0,000 . 2,519 0,013 X 24,568 0,326 0,991 1,000 75,435 0,000
Analysis of Variance Source SS df Mean Squares F-Ratio p-Value
Regression 1,257E+009 1 1,257E+009 5 690,403 0,000
Residual 21 654 624,388 98 220 965,555
Test for Normality
Test Statistic p-Value
K-S Test (Lilliefors) 0,067 0,295
Shapiro-Wilk Test 0,989 0,550
Anderson-Darling Test 0,395 > 0.15* *The p-value cannot be precisely computed.
Durbin-Watson D-Statistic 2,084 First Order Autocorrelation -0,049
Information Criteria
AIC 1 518,344
AIC (Corrected) 1 518,594
Schwarz's BIC 1 526,159
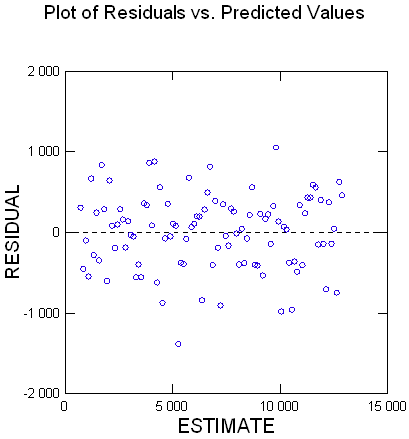
Je me demande, comme dans mes données il y en a une inhabituellement grande alors que dans ce test, elles sont réparties uniformément, si ça aurait un rapport ?
Je fais un essai en la retirant bien qu'elle semble bien ajustée : les x proche de 20 sont nombreux, ceux proches de ce maxi à 94 beaucoup moins.
En tout cas ici, le modèle de départ était 379 + 24x, avec une normale centrée d'écart-type 500, et à l'arrivée les programmes trouvent 254 + 24.6x.
Ceci dit la constante est dans l'intervalle de confiance.
Amitiés,
#41 Re : Café mathématique » Robustesse d'une régression linéaire » 16-10-2016 12:14:23
Salut Freddy, et merci de ton aide et attention.
A priori, ce modèle y=ax+b dans la limite de mes connaissances physiques devrait correspondre.
Il y a une incertitude sur la valeur de x à chaque observation pour des raisons circonstancielles inconnues, a priori aléatoire mais qui pour des raisons pratiques ne peut raisonnablement être inférieur à disons 8 et jamais supérieur à 110.
Je n'ai pas d'outil décrivant les autocorrélations, autre que des ACF et dérivés pour étudier des séries temporelles. Ici comme chaque paire peut être associée à une date, je viens de regarder mais je ne vois pas de pattern remarquable. Je ne sais pas comment voir si des autocorrélations d'ordre supérieur existent, ni comment "décorréler".
Que je comprenne bien avant de faire des simulations qui ne ressembleraient pas à celle que tu suggères ;
- je tire au hasard une centaine de valeurs de x, avec une loi quelconque conservant x entre 20 et 110, favorisant par réalisme quand même ce que j'ai avec les données de départ : moyenne 36.15, écart-type 20
- de là je calcule y avec ma formule douteuse actuelle 369+24.4 * x, douteuse mais qui est ce que j'ai de mieux en ce moment
- et j'ajoute une valeur aléatoire à y de moyenne nulle et variance quelconque, après quoi je refais le calcul de régression classique ?
Merci encore à toi de me prêter ton temps, amicalement,
#42 Re : Café mathématique » Robustesse d'une régression linéaire » 15-10-2016 18:20:09
@Dlzlogic
Bonsoir
@ D'abord vous posez une question purement mathématique sur un forum mathématique. La définition d'une régression linaire est très claire, et votre première question à propos de la non normalité des deux liste me laisse supposer que ces notions ne sont pas très claires pour vous.
Vous avez parfaitement raison, je pose une question purement mathématique sur un forum mathématique
Ça ne me paraît pas anormal.
Ensuite, et effectivement, la validité d'une régression utilisant la méthode des moindres carrés me posait problème, et j'ai eu des indications satisfaisantes même si dans mon cas précis, la question reste ouverte pour d'autres problèmes que la normalité des distributions (donc et à ce que j'en ai compris, entre autres l'égalité des variances).
Dire que la définition d'une régression linéaire, au sens où vous semblez l'entendre (les moindres carrés), ne me paraît pas si claire même si les contributeurs compétents indiquent que cette méthode est la moins entachée de biais.
Par exemple, un des programmes que j'utilise peut utiliser 22 méthodes de régression y compris bayésiennes.
Ensuite je ne crois pas être trop hors sujet, puisque dans l'exemple que je cite de votre cite vous semblez indiquer "au pif" que des données suivraient peut-être une loi normale, et ceci avec 12 valeurs.
http://www.dlzlogic.com/aides/DangerStat.pdf
Certes vous faites une mise en garde, mais quel "praticien" même de très loin voudrait déduire quoique ce soit d'un aussi petit ensemble, y compris que cet ensemble suit peut-être une loi normale ?
Et en plus c'est une série temporelle, ce qui ne me semble pas indifférent pour le calcul. Les 27 paires de données que je donnais en sont une aussi (les 9 premières paires sont ordonnées selon des dates croissantes non consécutives, les suivantes selon des jours toujours croissants consécutifs).
Si vous aimez tellement avoir des données réelles sur lesquelles travailler, je vous envoie très volontiers une série temporelle de 547 valeurs, qui correspond aux nombres de personnes reçues aux urgences d'un hôpital du 1.1.2015 au 30.6.2016, moyenne de 74,344 patients par jour et écart-type de 10,147 (toutes les dates sont consécutives).
Si vous aimez travailler sur de vraies données, je serais curieux de voir ce que vous ferez de celles là.
#43 Re : Café mathématique » Robustesse d'une régression linéaire » 15-10-2016 16:08:11
Bonjour,
Si on résume ce topic, ta question est "J'ai fait des calculs avec des données. Voici mes résultats, est-ce bon ? Mais je ne veux pas montrer mes données."
Moi, j'aurais une question : "Pourquoi parle-t-on de test alors qu'il s'agit de calculer une régression ?".
D'abord, quand j'écrivais ma thèse, ou mon mémoire, ou participais à l'écriture d'une quinzaine ou vingtaine d'articles (on me demandait entre autres mon avis sur la méthodologie de façon collégiale, ou à moi seul la réalisation de calculs statistiques, ou l'écriture de programmes de mesure en temps réel lors de différents tests), je ne me serais jamais permis d'aller demander à mon prof de stats avec qui j'avais des relations amicales, ou son assistant, de faire les calculs à ma place.
C'aurait été se moquer du monde.
La question (ou plutôt les questions) que je posais étaient souvent en premier la façon, selon les méthodes employées, d'obtenir des données qui soient éventuellement calculables ; ensuite et toujours sauf évidence, si j'utilisais un calcul statistique dans un domaine où il était valide, et sinon si on pouvait me suggérer un test valide (ce qui rejoint d'ailleurs la question préalable des données calculables, avant même le début de l'étude; pour les articles que je mentionnais, le coût des études était prohibitif, d'où la nécessité de ne pas les faire pour rien, et le corollaire regrettable qui est que le directeur d'études tient absolument à avoir un résultat positif, un article où l'auteur n'a rien trouvé est rarement publiable). Je ni'rais pas jusqu'à dire ce point a influencé la publication plus que douteuse de Seralini, mais ça n'est pas impossible.
Une exception cependant, une étude il y a quelques années sur la co-presription de médicaments sur des ordonnances de sortie d'hospitalisation. Sachant qu'une ordonnance peut aussi bien avoir deux lignes que 18, qu'évidemment co-prescription veut dire couplage non seulement de 2 médicaments mais aussi bien de 5, il a fallu recourir à des techniques de data mining, j'étais absolument incapable d'imaginer ne serait-ce que le début d'un algorithme calculant ça.
Dans ce cas donc, il m'a fallu me résoudre à solliciter le calcul effectif d'un statisticien du CHU de Nancy, à qui le prof en question m'avait recommandé.
A noter qu'ici on est en statistique surtout descriptive, même si on obtient un graphe, où à partir d'une association on a une intensité d'association vers un autre nœud où il y a éventuellement un médicament ou plusieurs de plus.
C'est avec ce genre de méthodes que Amazon ou autres vendeurs vont me proposer un article qui pourrait m'intéresser quand je me connecte (et encore en ce moment il y a comme un bug puisque Amazon me suggère d'acheter un article que je leur ai déjà acheté).
Sur votre question, que je ne comprends pas très bien, la réponse est peut-être justement ma question, ai-je le droit de faire une régression dans le cas que je cite.
Jusqu'ici, vous n'avez répondu en rien à ma question. Je ne vois pas en quoi vous fournir les données m'avancerait.
Par contre si Freddy en avait besoin, je n'hésiterais pas à les lui communiquer.
#44 Re : Enigmes, casse-têtes, curiosités et autres bizarreries » Impact de la foudre. » 15-10-2016 15:31:47
Bonjour Leon,
J'aurais bien proposé quelque chose comme (517, 371) pour le point d'impact,
mais la précision des données n'est pas tout à fait respectée...
Pour sortir un peu de cette discussion interminable, j'ai un programme de calcul statistique qui peut calculer des problèmes en 2D, et qui donne en exemple des données sur des relevés dans une région susceptible de receler des gisements d'uranium. Il me semble d'ailleurs qu'il y a eu un scandale au sujet d'une société qui a prétendu posséder de prétendus gisements aurifères à partir de données truquées, vers le début du 20ème siècle.
Bref mon programme sort un diagramme de Voronoi, avec différentes méthodes possibles dont celle de Krige
(cf. https://en.wikipedia.org/wiki/Mineral_r … stimation)
A ce que j'ai lu, il y a même eu des avancées spectaculaires en algorithmique dans les années 90 sur ce genre de problème.
Aurais-tu des notions sur ce genre de sujet ? (comme d'habitude, avoir l'outil comme moi, ne sert absolument à rien si comme moi aussi on n'a aucune base sur le sujet).
Bien amicalement,
#45 Re : Café mathématique » Robustesse d'une régression linéaire » 15-10-2016 14:35:19
Re-salut
Et 27 voire 26 paires d'information => je ne parierais même pas une vieille chaussette sur le pouvoir de prédiction du modèle, mais je sais qu'en biostat, c'est assez courant.
Notre vie ne tient parfois qu'à un fil :-)
C'est peut-être pour ça qu'en première année de médecine la matière était baptisée "biomathématiques" (on ne faisait rien que de très ordinaire, dérivées, intégrales, .. même pas avec des énoncés rappelant en quoique ce soit de la médecine ou de la biologie) et plus tard des "biostatistiques" (même chose, avec des problèmes du genre "combien de temps va t-on attendre le bus en moyenne")
:-)
Si la question t'intéresse, à l'occasion je t'enverrai un scan des brochures que laissent les labos pour vanter leur dernière m.. (simplement, fais-le moi savoir, j'ai fini par refuser de rencontrer les délégués médicaux, donc il faudra que je demande à des collègues de me prêter la réclame qu'on leur a donné.
@+
#46 Re : Café mathématique » Robustesse d'une régression linéaire » 15-10-2016 14:02:13
Bonjour
Bonjour,
Je crois que si on pouvait avoir les 27 ou 28 couples on pourrait discuter sur des valeurs et non sur des résultats de traitements inconnus.
Sincèrement, vous croyez que j'ai calculé à la main les tests de Lilliefors, Shapiro-Wilk, Anderson-Darling et celui de Durbin-Watson ?
Je me sers de XLStat (un add-on de Excel) et de Systat (un programme commercial, qui permet aussi d'autres types de régression).
Pour les moindres carrés, je dois avoir une calculette qui sait faire ça; Maple et Mathematica aussi.
Si je viens poser des questions sur ce forum, c'est justement que ce n'est pas le tout d'avoir des programmes de calcul dédiés aux statistiques, ou de calcul formel, ou des calculettes : encore faut-il les utiliser à bon escient, et c'est pour ça que je suis très content que Freddy ou Léon me donnent des indications.
#47 Re : Café mathématique » Robustesse d'une régression linéaire » 15-10-2016 13:04:26
Salut Freddy
refais tout, en l'état, c'est inexploitable (en particulier, les p-value te disent de tout jeter !).
Et poste un joli graphe, possible que les erreurs se comportent bien, au bénéfice du DW dont on doit trouver une table sur la toile.
Pour le R-deux, c'est la part de la variance expliquée par le modèle (les y chapeaux) sur la variance totale de la variable expliquée (les y). Comme montré par yassine, il faut en user avec précaution.
Et 27 voire 26 paires d'information => je ne parierais même pas une vieille chaussette sur le pouvoir de prédiction du modèle, mais je sais qu'en biostat, c'est assez courant.
Notre vie ne tient parfois qu'à un fil :-)
Je croyais que les p-value indiquées ne faisaient que montrer que les données ne suivent pas une loi normale ? et que seul le DW était important ?
J'ai déjà refait tout le calcul et les dernières valeurs avec leur p-value correspondent aux données rectifiées (donc en ayant rectifié cette donnée aberrante signalée par Systat qui était de fait une erreur de recopie, la valeur corrigée étant beaucoup plus proche de la prédiction). Systat ne me signale plus à présent qu'une "large leverage", cette donnée est certes inhabituellement grande mais l'autre de la paire aussi, et il n'y a pas d'erreur de copie ici.
J'essaye donc d'insérer en plus grand ce graphe des résidus-prédictions:
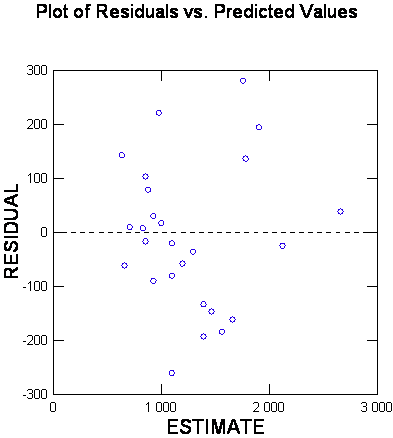
En passant, le test de Shapiro-Wilk me semble assez impitoyable et très souvent rejeter une loi normale, même sur 8 couples de données, existe t-il un moyen de connaître le risque beta de ce test ?
Amicalement, et merci à toi,
#48 Re : Café mathématique » Robustesse d'une régression linéaire » 15-10-2016 06:19:32
Salut Freddy
la p-value du K-S test (Lilliefors) me semble un peu élevée.
Avec une table pour le D-W, que valent d1 et d2 avec la taille de ton échantillon ? Tu sais qu'il y a des zones d'incertitudes, vérifie que tu n'est pas dedans. As-tu fait le graphe des résidus. S'il y a autocorrélation, ça saute aux yeux, comme pour l'indépendance d'ailleurs.
A vrai dire, je ne sais pas comment je m'y suis pris, mais j'ai repris le fichier avec l'"outlier" ce qui n'arrange rien. De fait j'ai aussi 27 paires et pas 28, la 1ère ligne étant le nom des variables..
Le graphe des résidus vs les prédictions est (excuse moi si c'est tout petit, c'est la première fois que j'insère une image..):
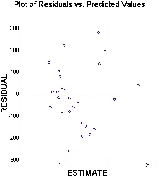
Et les valeurs obtenues sont en fait :
Test for Normality
Test Statistic p-Value
K-S Test (Lilliefors) 0,097 0,787
Shapiro-Wilk Test 0,188 0,000
Anderson-Darling Test 0,211 > 0.15* *The p-value cannot be precisely computed.
Durbin-Watson D-Statistic 1,645 First Order Autocorrelation 0,141
Information Criteria
AIC 348,060
AIC (Corrected) 349,104
Schwarz's BIC 351,948
A ma honte je n'ai pas trouvé de table pour Durbin-Watson..
Amitiés,
#49 Re : Café mathématique » Robustesse d'une régression linéaire » 14-10-2016 19:25:46
Bonsoir Léon,
En général, corrélation n'implique pas causalité. Donc il faudra faire une preuve de cette relation. Mais ça, je pense que tu le sais, je ne t'apprends rien. :)
Dans ce cas précis, on a toute raison de modéliser comme suit
y = a + b*x
C'est avec ce modèle que j'ai une corrélation plutôt élevée entre y et x, et je n'imagine pas d'autre facteur pertinent que y et x, juste des imprécisions sur chacun des deux.
Amicalement
#50 Re : Enigmes, casse-têtes, curiosités et autres bizarreries » Impact de la foudre. » 14-10-2016 18:17:18
Salut,
Tiens, supposons aussi bien que l'une de 4 caméras est en panne, ou 2 et pourquoi pas 3, l'énoncé ne l'interdit pas (peut-être 3 comme le lieu de la foudre serait calculable).
Amicalement